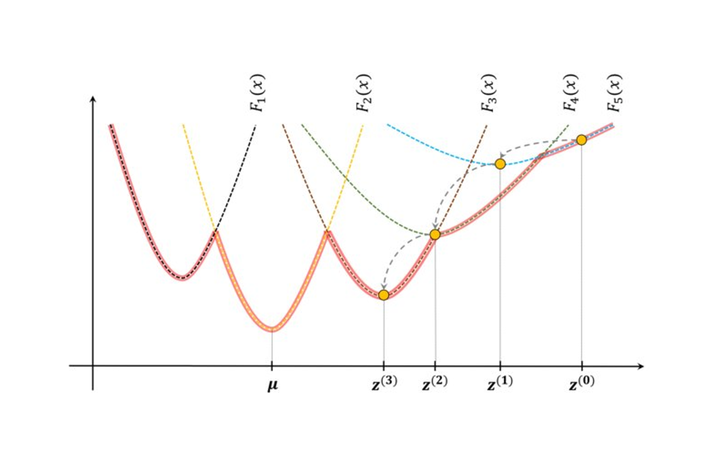
 Simplified depiction of the Fréchet function F of the LPI sample mean.
Simplified depiction of the Fréchet function F of the LPI sample mean.Abstract
The sample mean is one of the most fundamental concepts in statistics with far-reaching implications for data mining and pattern recognition. Household load profiles are compared to the aggregated levels more intermittent and a specific error measure based on local permutations has been proposed to cope with this when comparing profiles. We formally describe a distance based on this error, the local permutation invariant (LPI) distance, and introduce the sample mean problem in the LPI space. An existing exact solution has exponential complexity and is only tractable for very few profiles. We propose three subgradient-based approximation algorithms and compare them empirically on 100 households of the CER dataset. We find that stochastic subgradient descent can approximate the mean best, while the majorize-minimize mean is a good compromise for applications as no hyperparameter-tuning is needed. We show how the algorithms can be used in forecasting and clustering to achieve more appropriate results than by using the arithmetic mean.
Marcus Voss
Responsible AI Lead and AI Engineer
Dr.-Ing. | Responsible AI Lead at Birds on Mars | Green AI Co-Lead at KI Bundesverband